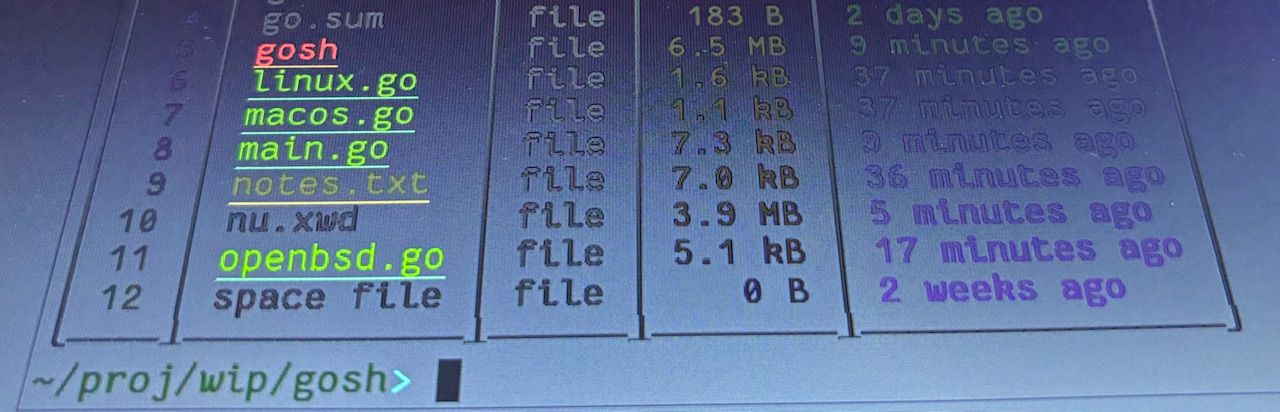
writing a little gosh
I had the idea to write a little shell in go. Called gosh, of course. There’s a few people playing with the same theme, but nothing exactly the same.
The idea is we have all these commands outputting data and processing it, and the unix ideal where everything is a beautiful line of text is awkward to process. That’s why they called it awk. What if the data were structured in some way, so that I can sort ls output by file owner, even if ls doesn’t offer that, and without counting columns and hoping they’re always the same?
So, uh, pretty much PowerShell. I had a plan to do this in luajit for some time using ffi for integration, because it’s already got the interpreter builtin, but running the shell from inside the interpreter gets bizarre. Go has pretty good facilities for interfacing with the system, too, but also a half decent reflect package, so I can work with structured data, but in a generic way.
gosh
My approach to gosh was to generally follow the existing paradigm so that commands I’m used to typing will still work in approximately the same way, but also in a way that fixes the gotchas that still catch me out after all these years. I figured it’s worth looking at nushell but wowza I hope I don’t have to implement all that.
There are several areas one can explore and learn when writing a shell. I don’t necessarily want to learn more about process groups and job control, so we’ll skip that stuff. And today is not the day for innovative parsing techniques, so that’s not going to be much more than string split. I just want to play around with passing data between to and between commands.
globs
About once a year, I run grep with a regex that happens to match a filename and hilarity ensues. At least once a month, I run curl with a url that happens to contain a & and the shell says, oh, oh, I know what that is, that’s for me, and my day is ruined.
Now as we all know, the shell should always expand globs because that is the proper real man unix way, and only stupid winblows makes each program expand argv, but reviewing my shell history, I run a lot of commands that take arguments that are not file names and for which glob expansion is not helpful. We already make every program run getopt itself, because the shell doesn’t know which flags are which.
In gosh, command line arguments are the equivalent of execv arguments, passed without interpretation. So ls will get *.go and expand that itself. It’s not implemented, but yes, mv *.jpeg *.jpg will finally be possible.
pipes
Every command gets an input channel and an output channel. The rules are you drain input (so the previous command can make progress) and close output (so the next command can finish). This is a little different from usual unix pipelines. Normally, if you run “ls | ps | df” then ls will write some data, but ps won’t bother reading it. Instead, when ps exits, it closes the pipe and ls gets SIGPIPE. (Side notes: go auto handles SIGPIPE. rust auto ignores SIGPIPE.)
Along those lines, “pipeline” utilities like sort only take behavioral arguments. I can’t recall ever running “sort filename”. Sorting is only done as part of a pipeline, and in the case where the ultimate origin was a file, 1000:1 I ran grep first. To save some implementation work, I’ve forgone the missing filename or “-” means stdin or stdout dup2(1, 3) incantations. In this house, we believe every cat is useful.
The current gosh implementation is wasteful, in that ls will continue feeding output to a dummy consumer. Instead, I could have ps close the input channel, contra to the go convention that only writers close channels. This will cause ls to panic on the next send, and then the whole ship goes down, which is not ideal. However, it’s possible to recover the panic.
Using go channels as unix pipes helped clarify the behavior of channels. I always found it confusing trying to remember when a go channel would block, or panic, or succeed. But they’re just pipes! Writing to a closed pipe results in SIGPIPE (and sudden death). Reading or writing an open pipe will block until something happens. Reading from a closed pipe will always return immediately. I never quite made the connection.
rows
I started with distinct types for the output of each command. Types are good, and strong types are best, right? And with some enterprise grade reflection, it’s possible to filter and sort them. And we can even print them nicely, using some hints in the struct tags. Like many bad ideas, this one seemed to have a lot of merit.
type FileInfo struct {
Mode fs.FileMode `fmt:"%-10s"`
Size int64 `fmt:"%10s"`
ModTime time.Time `fmt:"%-19s"`
Name string
}Unfortunately, after running a filter to select just size and name, I now have a slice of [int, string] and no means to print this intelligently. This can be solved, since reflect allows one to conjure up new struct types at run time, but I had the feeling there would always be one more fix, just one more tweak, it’ll work now for sure.
Sometimes the appropriate type really is the floppy sack of stuff. I made a new Row type which carries some information about its contents, but there’s only one type for all commands to use.
type Row struct {
columns *Columns
values []any
}Now commands like filter can copy over the columns. The column types are carried in the row, not the value, because this makes it possible to tell when the columns have changed, such as when netstat switches from inet to unix sockets. Whenever print sees a new set of columns, it prints a header.
This change made life a lot simpler, and I don’t think I lost anything. I hadn’t yet written any commands which require a FileInfo as input, and I’m not sure I ever will. Individual columns still have types, like FileMode, which is the important bit.
errors
There’s no error channel. Instead, you just send the error type into the output channel. Mixed thoughts on this. On the one hand, having stderr being a separate output from stdin has been an endless source of frustration for me. I never remember to redirect it, or do it wrong, and then a week later I find a file named 1 with a bunch of errors in it.
In gosh, a command can distinguish errors by casting to error if it cares, and then pass it along, or eat it, or process it. They get printed in order by default, which I find much more helpful, so I can see what the command was up to when the error occurred. If you run ls with a mix of existing and nonexistent files, the errors will appear in the same order as the input names.
There are probably downsides to this approach, but just having distinct types for errors means it’s not that difficult to work with.
next
Having implemented the very basics and proven the concept, what do I want to do next? There are a lot of programs in /usr/bin, and they each have a lot of options. gosh will only really be useful if it implements most of their functionality natively, but as I discovered, just checking the wifi status programmatically takes a while digging through system headers and source. A program like ifconfig would be a prime candidate for structured input and output, but also a substantial endeavor.
tcpdrop
I wasn’t quite ready to give up. Just one more command, I promise, then it’s done, I just need one more command. Occasionally, I find somebody abusing my web server, and I run pfctl to give their IP a banana, but by itself this doesn’t disconnect their existing session. They’ve been attempting to download /flak/.git every two seconds for the past six hours, with no signs of stopping soon, and I would like that to end. That’s where tcpdrop comes in. But now I need to know the port numbers, so I have to run netstat and grep and copy and paste. It’s not the end of the world, but I figured this would be a good candidate to implement. (Or you just run pfctl -k).
So now there’s a tcpdrop command in gosh, and it reads IP quadruples from input as output by the builtin netstat. The arguments are always correctly formatted and ordered, etc., because they are named and structured. So, there, I did a thing. It is, in some small way, better than the existing tools, but man was it a lot of work to get here.
ports
Go includes the basic functions you might want to implement ls, but you quickly discover that file info doesn’t include uid. But they punched in a backdoor, so you can use stat := info.Sys().(*syscall.Stat_t) to get it.
On OpenBSD, getting all the processes for ps is as simple as calling kvm_getprocs and netstat is just calling kvm_getfiles.
On MacOS, getting processes is possible via sysctl (which is what kvm_getprocs uses), but some info is missing unless you do some weird mach magic, and I have no idea about netstat. The file sysctl seems incomplete.
On Linux, you read files in procfs, such as /proc/1/stat. The man page helpfully suggests scanf formats to use, but doesn’t tell you that the second field can contain spaces. The only correct way to parse this is to scan forward looking for (, then scan backwards from the end looking for ), and take everything in between.
tedu@penguin:/proc/11427$ cat stat
11427 (what now) S) S 11350 ...Socket info is available via /proc/net/inet, but I ran into a quirk. Some of the fields in this file are space padded. The default go function I reach for is strings.Split but that will return empty fields. It’s not a big deal, just an awkward gotcha. Tools like awk and sort are fine with long strings of blanks. Time for a regex.
future
Back to the big question, what next? It was a fun experiment, but it’s just a toy, and even with my one useful hack added, it fills a very niche purpose. Turning /usr/bin into functions remains a daunting task. And what if somebody doesn’t like the syntax I use, and wants to make a slightly different shell? Will they have to reimplement everything as well? At least people switching from csh to ksh to fish know that all the stuff outside the shell still works the same way. When everything is inside the shell, oof.
I can’t help but think we’re missing something. All this functionality trapped in programs. The output of ifconfig should just be a thing I can grab and work with, and then send back to effect change. Actually, the sysctl mechanism is pretty handy for some things. What if it were, somehow, more expansive?
FreeBSD briefly experimented with libxo to add structured output to utilities. It’s technically still there, but neither ls, nor stat, nor find support it. Utilities like sort aren’t json aware, but that’s fine as long as we have jq. Except nothing is linked with libxi for input. We’d like “ls | jq | rm” to work without xargs. Otherwise we’re just replicating old problems in new ways. (There’s ten years of issues on the jq github discussing variations on -print0 functionality, but --raw-output0 arrived in 1.7.0.) Also, it needs to work with latin-1 file names. Or ifconfig. As silly as it may be, I should be able to run ifconfig, add 64 to every IP, and then change every interface. This is an awkward scripting challenge.
nushell
I also ran nushell a few times to see how it behaved. This wasn’t really meant to be an exhaustive examination. Just run a few commands, and see if they did anything cool I wanted to copy, or anything uncool to avoid.
Start with ls.
~/proj/wip/gosh> ls main.go
╭───┬─────────┬──────┬────────┬────────────────╮
│ # │ name │ type │ size │ modified │
├───┼─────────┼──────┼────────┼────────────────┤
│ 0 │ main.go │ file │ 7.1 kB │ 25 minutes ago │
╰───┴─────────┴──────┴────────┴────────────────╯
~/proj/wip/gosh> ls -l main.go
╭───┬─────────┬──────┬────────┬──────────┬───────────┬───────────┬───────┬─────╮
│ # │ name │ type │ target │ readonly │ mode │ num_links │ inode │ ... │
├───┼─────────┼──────┼────────┼──────────┼───────────┼───────────┼───────┼─────┤
│ 0 │ main.go │ file │ │ false │ rw-r--r-- │ 1 │ 15383 │ ... │
│ │ │ │ │ │ │ │ 12 │ │
╰───┴─────────┴──────┴────────┴──────────┴───────────┴───────────┴───────┴─────╯Okay, but where did the size go? It’s buried behind .... This will come back to haunt me.
The table grid with all the lines looks cool at first, but I think it’s too busy, and I don’t like that the columns will change size based on input. I’m used to scanning a certain area of the screen. Consider this example. Depending on directory, the “type” column can be inside where the “name” column was. If I’m tracking the size column, now I have to count columns again to find it.
~/work/nushell> ls | head -5
╭────┬─────────────────────┬──────┬──────────┬────────────╮
│ # │ name │ type │ size │ modified │
├────┼─────────────────────┼──────┼──────────┼────────────┤
│ 0 │ CITATION.cff │ file │ 812 B │ 3 days ago │
│ 1 │ CODE_OF_CONDUCT.md │ file │ 3.4 kB │ 3 days ago │
~/work/nushell> ls / | head -5
╭────┬────────┬─────────┬────────┬──────────────╮
│ # │ name │ type │ size │ modified │
├────┼────────┼─────────┼────────┼──────────────┤
│ 0 │ /bin │ symlink │ 7 B │ 2 years ago │
│ 1 │ /boot │ dir │ 0 B │ 2 years ago │Also, I would say it’s definitely wrong to output the full table header to random external programs. This just repeats all the mistakes of having to strip formatting in my awk script. The output of nushell’s ls is a disaster for awk parsing. I like the idea of pretty printing the end of a pipeline (perhaps less garishly), but not in the middle.
I wanted to see the big files.
~/proj/wip/gosh> ls | where size > 100 Error: nu::shell::operator_incompatible_types
× Types 'filesize' and 'int' are not compatible for the '>' operator.
╭─[entry #10:1:1]
1 │ ls | where size > 100
· ─┬ ┬ ─┬─
· │ │ ╰── int
· │ ╰── does not operate between 'filesize' and 'int'
· ╰── filesize
╰────Come on. How is this helpful? Stuff like this kills me. Are we trying to make things better, or just harder? Plus one point for an artisanally crafted error message, minus ten points for making it an error.
In my searching for filesize documentation, I came across the format function.
~/proj/wip/gosh> help format filesize
Converts a column of filesizes to some specified format.
Examples:
Convert the size column to KB
> ls | format filesize KB size
~/proj/wip/gosh> ls | format filesize KB size
Error: nu::shell::invalid_unit
× Invalid unit
╭─[entry #32:1:22]
1 │ ls | format filesize KB size
· ─┬
· ╰── encountered here
╰────Sigh.
That’s only half the story. Let’s consider ps. It works, but it shows me everything. I only want to see my processes.
~/proj/wip/gosh> ps | where uid == 1000
Error: nu::shell::name_not_found
× Name not found
╭─[entry #2:1:12]
1 │ ps | where uid == 1000
· ─┬─
· ╰── did you mean 'pid'?
╰────
~/proj/wip/gosh> ps | where user == 'tedu'
Error: nu::shell::column_not_found
× Cannot find column 'user'
╭─[entry #3:1:12]
1 │ ps | where user == 'tedu'
· ──┬─┬
· │ ╰── value originates here
· ╰── cannot find column 'user'
╰────It’s a bit weird that this results in two different error codes?
Actually, this gives me an idea for some of my own C code. Change all the int return values to float. Most of the time it will still return -1 for errors, but sometimes it will return -0.1 to indicate you were really close to success. EGETTINGWARMER.
Okay, back to the main quest, what is the uid column called? Alas, there are limits to how wide a terminal and how small a font I’m willing to adopt.
~/proj/wip/gosh> ps
╭────┬───────┬───────┬──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬─────╮
│ # │ pid │ ppid │ name │ ... │
├────┼───────┼───────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼─────┤
│ 0 │ 1 │ 0 │ /sbin/init │ ... │
│ 1 │ 831 │ 86157 │ -ksh │ ... │
│ 2 │ 1978 │ 64428 │ chrome: --type=utility --utility-sub-type=network.mojom.NetworkService --lang=en-US --service-sandbox-type=network │ ... │
│ │ │ │ --enable-crash-reporter=, --shared-files=network_parent_dirs_pipe:100,v8_context_snapshot_data:101 │ │
│ │ │ │ --field-trial-handle=3,i,616797960757361012,14564804509186941996,262144 --variations-seed-version │ │...
We might consider why /bin/ps always prints the command last. For the indiscretion of running chrome, I am now forbidden to ever filter or sort processes by uid or even learn the names of the unknowable columns. But what if I’m not the one running chrome, and it’s some other bastard user, and I only want to see my processes? No. Forbidden.
Please, modern software, I’m begging you, stop saving me from myself. Sometimes it’s okay to let the bad thing happen. Where the bad thing is printing a line longer than the terminal.
Another funny thing nushell does is that all the names of source files are printed in lemon juice invisible ink to prevent corporate espionage.
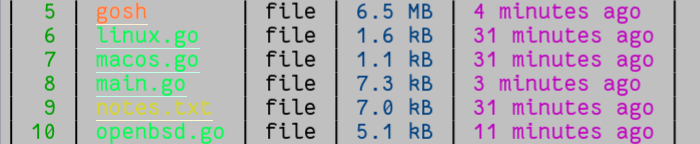
Fortunately, I have a TN panel and if I tilt the screen to just the right angle, the secrets are revealed.